Sign Language Detection using Mediapipe and LSTM
An implementation of sign language detection using an LSTM NN built on TF Keras with the help of Google's Mediapipe.
Explore the docs »
Report Bug
·
Request Feature
Table of contents
About the project
LSTM, or long short-term memory, is a type of recurrent neural network (RNN) that is well-suited for detecting and translating sign language. LSTM networks are able to retain long-term memory and can therefore better recognize patterns in sequential data, such as the movements of a person’s hands and body in sign language.
To use LSTM for sign language detection, you would need to train the network on a large dataset of videos or images of people signing. The network would then be able to recognize the signs and convert them into text or audio output. This process would require a significant amount of data and computational power, but could potentially be very effective for sign language translation.
MediaPipe is a framework for building multimodal (e.g., video, audio, and text) machine learning pipelines. It can be used for sign language detection by building a machine learning model that is trained on a dataset of sign language videos or images. The model could then be incorporated into a MediaPipe pipeline for real-time sign language detection and translation.
To use MediaPipe for sign language detection, you would first need to create and train a machine learning model that is capable of recognizing signs in video or image data. This could be done using a variety of techniques, such as convolutional neural networks (CNNs) or recurrent neural networks (RNNs) like LSTM.
Once the model is trained, it can be incorporated into a MediaPipe pipeline for real-time sign language detection. The pipeline would take in video data as input and output the detected signs in text or audio form. This could be useful for applications such as real-time sign language translation or automatic captioning of sign language videos.
Mediapipe
MediaPipe combines individual neural models for face mesh, human pose, and hands and has a total of 543 landmarks (33 pose landmarks, 468 face landmarks, and 21 hand landmarks per hand). All landmarks consist of $x$, $y$, and $z$ coordinates, except pose landmarks, which consist of a visibility coordinate along with $x$, $y$, and $z$ coordinates.
Hand Landmark Model

LSTM Model
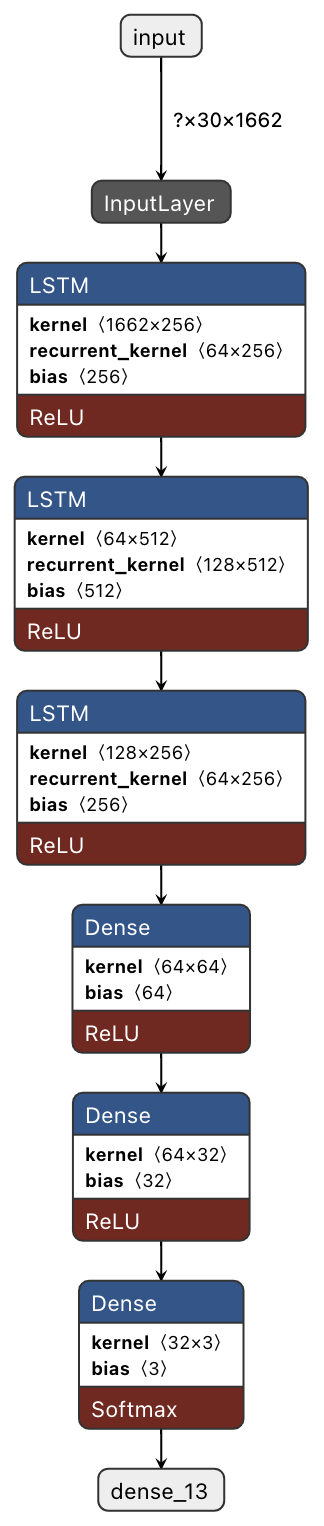
Considered three layers of LSTM, each with 64, 128, and 64 nodes, with ReLU as the activation function for each layer. The stacked LSTM structure allows for deeper training so that more complex input patterns can be extracted at every layer with disabled return sequences in the final LSTM layer. This is due to the fact that only the output of the last hidden layer is passed to the next Dense layer. In addition to this, there are three layers of fully connected networks, each with 64, 32, and 3 units, respectively. Since the output is one of our defined actions, the last Dense layer has a unit size corresponding to the number of actions defined. A categorical cross entropy was used as the loss metric.
Results
LSTM Model Summary
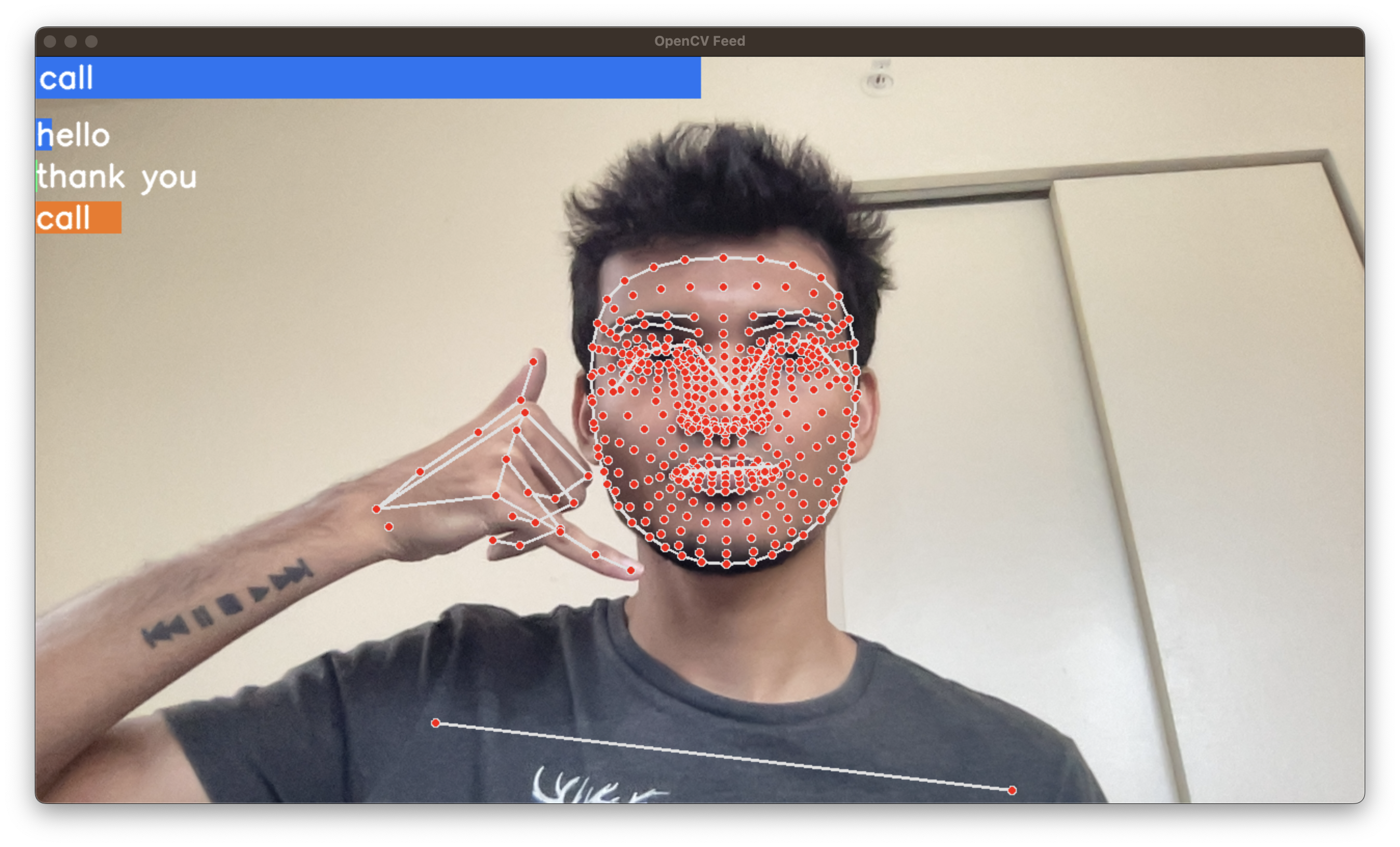
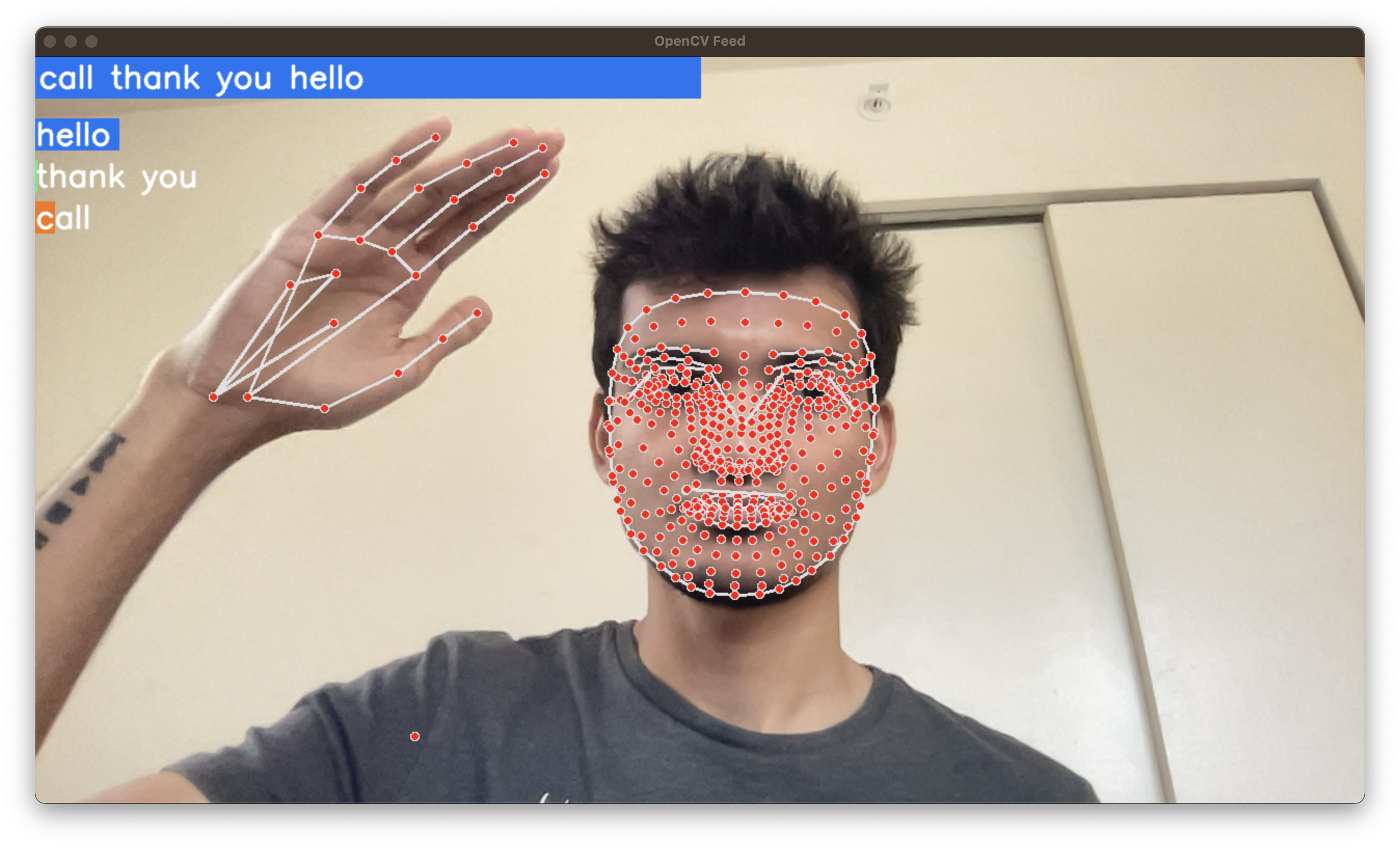
Real-Time Sign Language Detection

References
- CM. Rajalakshmi Sachin Agrawal, Agnishrota Chakraborty. 2022. RealTime Hand Gesture Recognition System Using MediaPipe and LSTM. International Journal of Research Publication and Reviews (2022). pdf -